
The Problem
Skincare is one of the few domains where popular advice is actively wrong. People layer retinol with AHAs, stack vitamin C with benzoyl peroxide, and use multiple exfoliating acids in a single routine — combinations that dermatologists have documented as causing barrier damage, reduced efficacy, and irritation. The information exists, but it's scattered across Reddit threads and ingredient databases that require significant domain knowledge to interpret.
The broader issue is that skincare marketing sells products in isolation. A routine is never one product — it's the interaction of five to ten products applied in sequence, where the ingredient lists overlap, conflict, and compound each other's effects. There was no tool that treated the routine as the unit of analysis rather than the individual product.
The Solution
DaisyDerm is a web app that takes a user's complete routine — AM or PM, with real products from a Supabase database or custom ingredient lists — and runs it through a rule-based analysis engine built on dermatological ingredient science. The engine detects conflicts, redundancies, missing essentials, and optimal layering order, then computes a 0–100 routine score and a 0–10 barrier stress index. Products are sourced from the Open Beauty Facts API and a curated local database, with Brave Search as a fallback for ingredient lookup.
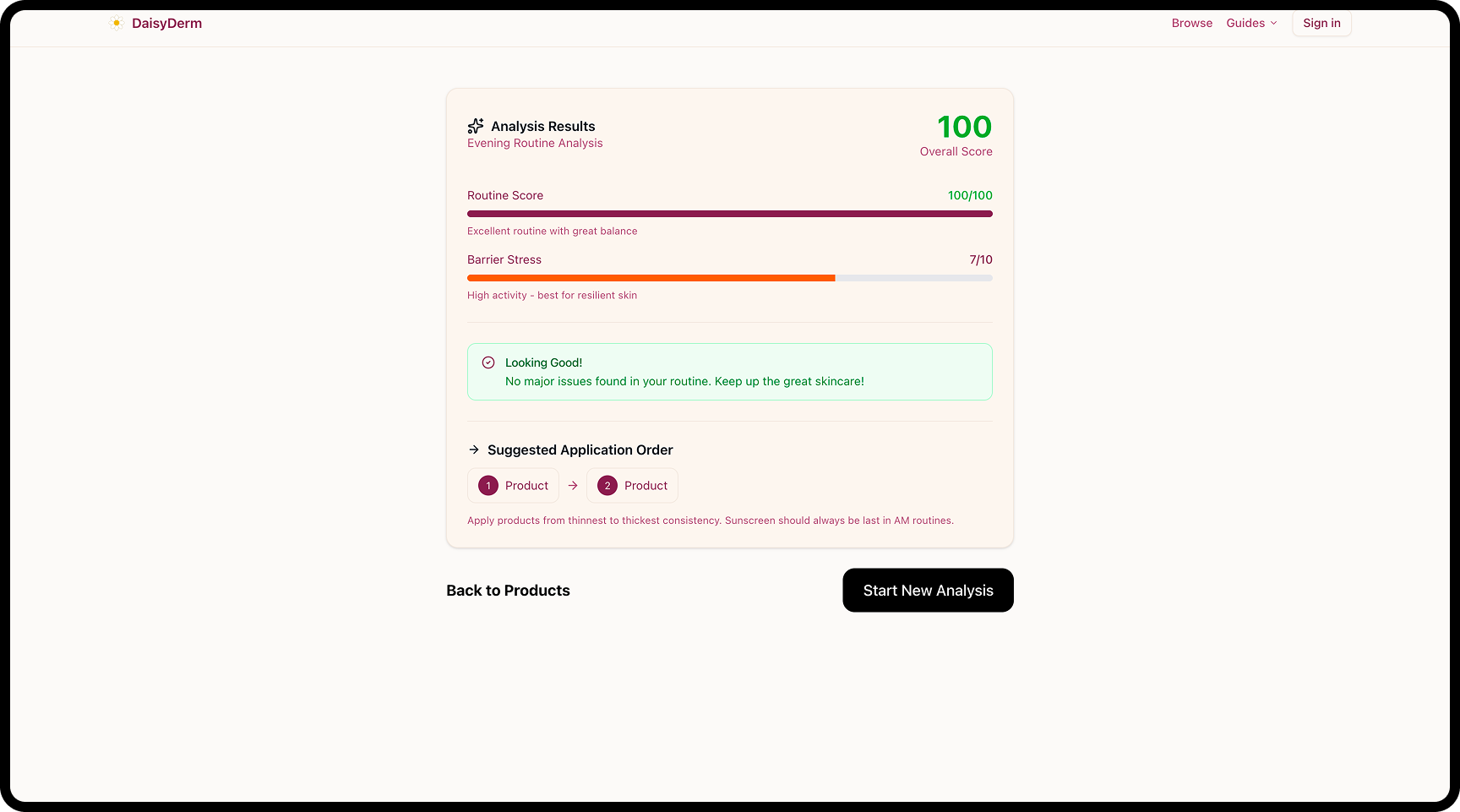 Routine analysis results — overall score (0–100), barrier stress index (0–10), detected conflicts with severity, missing essentials, and suggested layering order
Routine analysis results — overall score (0–100), barrier stress index (0–10), detected conflicts with severity, missing essentials, and suggested layering order
Subcategory-level and ingredient-level conflict detection — retinoid/AHA, BPO/retinoid, multiple acids, and more — with severity ratings (high/medium/low).
Thin-to-thick layering order from cleanser to sleeping mask, with AM/PM filtering and per-category explanations surfaced in the UI.
Ingredients, products, product_ingredients, routines, and routine_items — with GIN trigram indexes and full Supabase RLS policies.
Oily, dry, combination, normal, and sensitive — each with ingredient-level penalty rules that feed into the overall score calculation.
Next.js App Router with Server-Side Analysis
DaisyDerm is a Next.js 16 App Router application. The multi-step analysis wizard runs entirely client-side — state managed through a React context that persists routine type, skin type, and product selections across route transitions. When the user submits for analysis, the client posts to /api/analyze, a Next.js Route Handler that instantiates a Supabase server client, validates the payload with Zod, and runs the analysis engine entirely on the server before returning the result. No external AI service — the analysis is deterministic rule-based logic in TypeScript.
Client
/api/analyze
Products + Ingredients
Validation
Engine
Query
GIN Index
Facts API
Parse
Returned
Stack Overview
| Layer | Technology | Role |
|---|---|---|
| Framework | Next.js 16, React 19, TypeScript | App Router; Route Handlers for API; server components for product/guide pages |
| Styling | Tailwind CSS v4, Radix UI, shadcn/ui | Utility-first styling with accessible, headless component primitives |
| Database | Supabase (PostgreSQL), pg_trgm |
Ingredient reference + product catalog + user routines; RLS for auth-gated data |
| Auth | Supabase Auth, @supabase/ssr |
Session-based auth with middleware-gated routes; routines scoped to auth.uid() |
| Validation | Zod 4 | Request schema validation at the Route Handler boundary; input schema per wizard step |
| Content | MDX, next-mdx-remote, gray-matter |
Skincare guides authored in Markdown with frontmatter, rendered as server components |
| External APIs | Open Beauty Facts, Brave Search | OBF for product and ingredient data import; Brave Search as ingredient lookup fallback |
Multi-Step Analysis Wizard
The analysis flow is a four-step wizard spread across separate Next.js routes, with state persisted in a React context. Each step advances through router.push() — routine type selection, skin type selection, product building, then analysis results. The context survives route transitions so no data is lost between steps, and users can go back to modify selections without losing their product list.
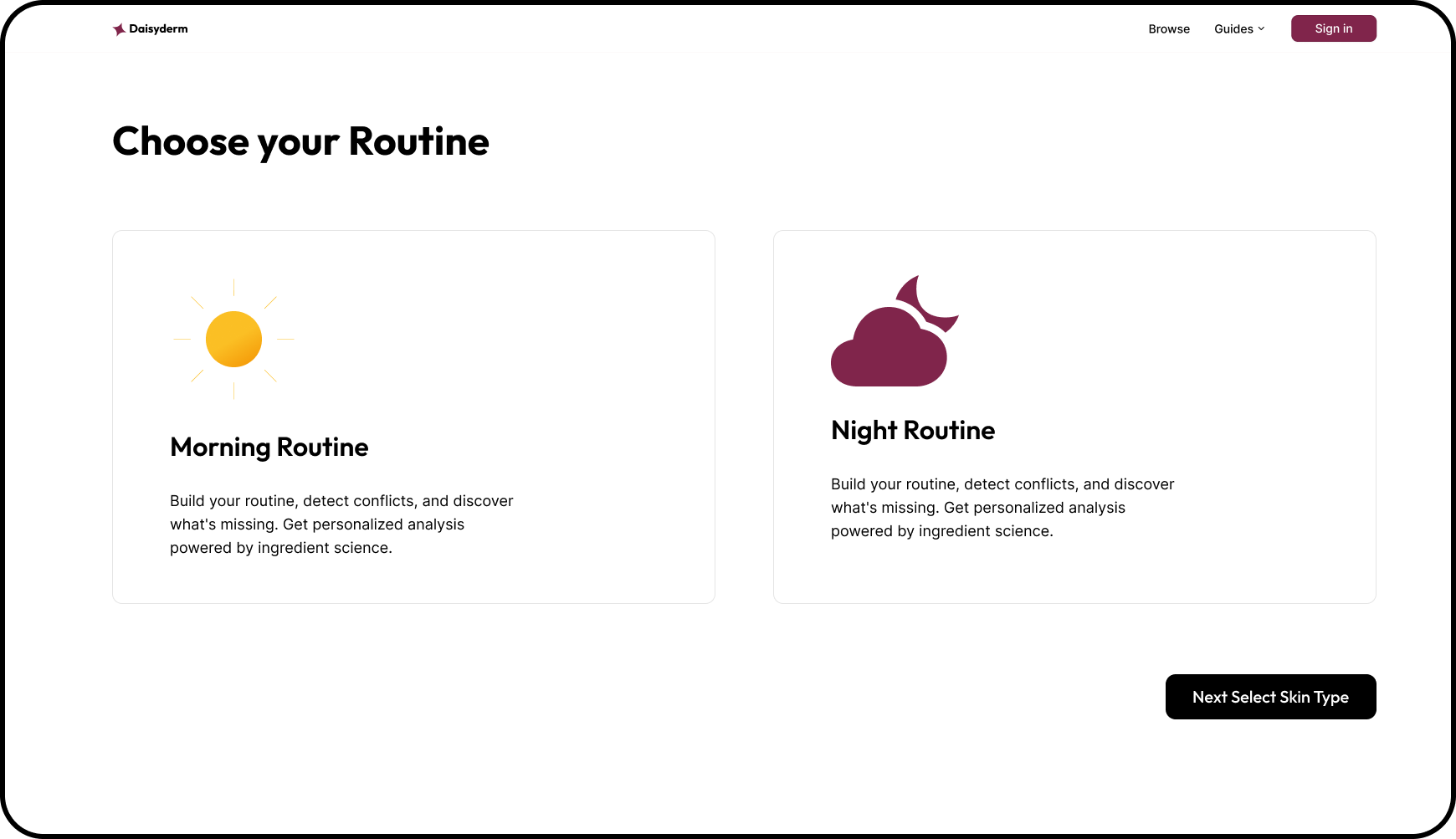 Step 1 — routine type selection (AM/PM); drives which missing essential rules apply (sunscreen for AM, cleanser for PM) and which product categories are filtered in layering order
Step 1 — routine type selection (AM/PM); drives which missing essential rules apply (sunscreen for AM, cleanser for PM) and which product categories are filtered in layering order
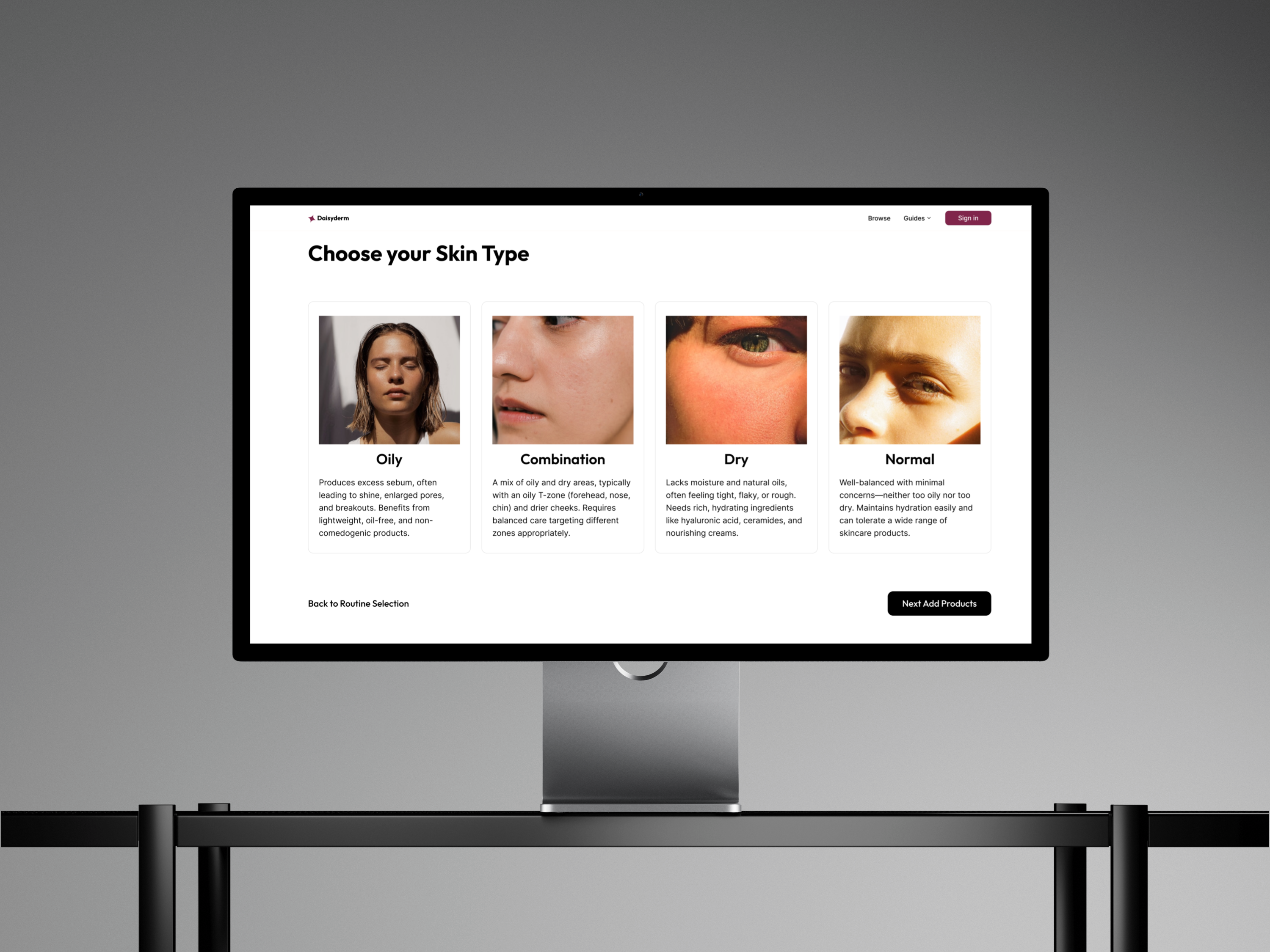 Step 2 — skin type selection; feeds skin-type-specific penalty rules into the overall score calculator (heavy occlusives penalised for oily, stripping alcohols for dry, sensitizing ingredients for sensitive)
Step 2 — skin type selection; feeds skin-type-specific penalty rules into the overall score calculator (heavy occlusives penalised for oily, stripping alcohols for dry, sensitizing ingredients for sensitive)
Routine Analysis Engine
The analysis engine lives in src/services/analyzer/ as six independent modules. Each module handles one concern and returns a typed result that the orchestrator aggregates into a single AnalysisResult object. The engine handles both database products (fetched with their full ingredient lists) and custom products (built from raw ingredient text entered by the user).
Two conflict detection passes: subcategory-level (retinoid+AHA, BPO+retinoid, etc.) and ingredient-level (checks for retinol, retinal, L-ascorbic acid, glycolic acid, BPO by INCI name). Deduplicates results across both passes so the same product pair is never reported twice.
Checks for essential category presence by routine type. AM requires sunscreen (high severity) and moisturizer (medium). PM requires cleanser (medium) and moisturizer (medium). Each missing essential subtracts from the overall score proportional to severity.
Enforces per-subcategory count limits — one retinoid maximum (high severity), one vitamin C (medium), one AHA (high), one BHA (medium), up to two hydrating serums (low). Also catches >2 cleansers (breaks double-cleanse logic) and multiple sunscreens.
Sorts products by category position in a 12-step thin-to-thick order, then filters out AM-only (sleeping_mask) or PM-only (sunscreen) products based on routine type. Returns ordered product IDs and per-category explanation strings.
Two outputs: barrier stress (0–10, from irritation scores × position weights + active-category penalties) and overall score (0–100, from base 100 with deductions for all issue types and skin-type penalties, plus bonuses for sunscreen, moisturizer, fragrance-free, and skin-appropriate choices).
Single source of truth for all rule data — MISSING_RULES, CONFLICT_RULES, REDUNDANCY_RULES, LAYER_ORDER, and LAYER_NOTES. Changing a conflict rule or adding a new essential requires editing one file, not hunting through logic scattered across modules.
Ingredient Conflict Rules
Nine conflict rules cover the most clinically documented ingredient interactions in skincare. Severity levels (high / medium / low) determine both the UI presentation and the score deduction — high conflicts subtract 15 points, medium 10, and low 3.
Layering Order Suggestion
The layer suggester sorts the user's products into the dermatologically recommended thin-to-thick application order. Products are categorised on import and sorted by their position in a fixed 12-step sequence. Sunscreen is filtered to AM only; sleeping masks to PM only.
Open Beauty Facts Product Integration
Rather than maintaining a manually curated product database, DaisyDerm integrates directly with the Open Beauty Facts (OBF) API — an open-source cosmetics database with millions of product entries. When a user searches for a product and it's not in the local database, the OBF lookup service is called in real time, the product is parsed and categorised, imported into Supabase, and returned in the same response.
Product search queries Supabase using a relevance scoring algorithm — exact name matches, starts-with, contains, and word-overlap scoring — backed by a GIN trigram index on normalized_name for fast fuzzy matching. Results are ranked by relevance score descending.
If the local search returns no results, the OBF service queries world.openbeautyfacts.org with the search term. A 600ms rate limiter prevents exceeding the API's ~100 req/min limit. OBF responses are parsed to extract brand, product name, ingredient list (from INCI text), country of origin, and image URL.
Each OBF product is classified into DaisyDerm's category/subcategory taxonomy using a brand configuration file and keyword heuristics. Fragrance-free and sensitive-friendly flags are derived from the ingredient list. The parsed product — with all ingredient positions — is upserted into Supabase and returned to the client as a usable product in the same request.
When neither the local DB nor OBF returns useful ingredient data — common for niche or regional brands — a Brave Search API query fetches ingredient lists from the web. Rate-limited to 1.1 seconds between requests (Brave free tier cap). Results are returned as raw search snippets for the user to review rather than being imported automatically.
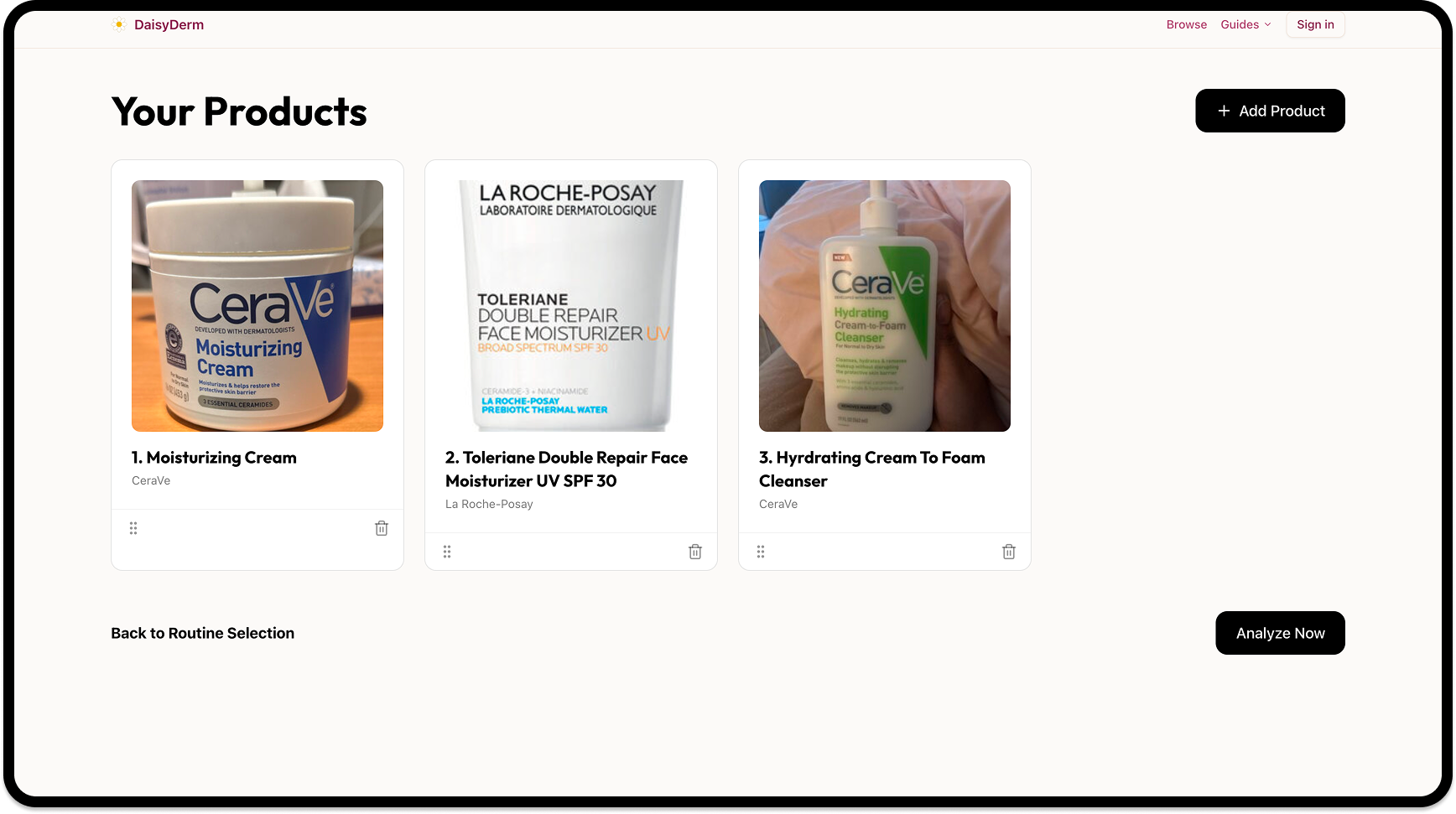 Product catalog — products sourced from OBF imports and manual additions; category filtering backed by Supabase indexed queries; each product card links to a detail view with full ingredient list
Product catalog — products sourced from OBF imports and manual additions; category filtering backed by Supabase indexed queries; each product card links to a detail view with full ingredient list
Key Engineering Decisions
Rule-Based Engine, Not an LLM
The analysis engine is entirely deterministic — no AI API calls, no probabilistic outputs. Every conflict, redundancy, and missing essential has a specific, citable rule with a defined severity. This was a deliberate design choice: skincare ingredient interactions are well-documented in dermatology literature, and a deterministic system can explain exactly why it flagged something. An LLM would produce plausible-sounding but inconsistent results across identical routines, and it would be impossible to audit whether the flagging logic was actually correct. Rule-based also means zero latency on the analysis itself — the only network call is fetching product data from Supabase.
Two-Pass Conflict Detection (Subcategory + Ingredient-Level)
Conflict detection runs in two distinct passes that are then deduplicated. The first pass checks subcategory pairs (retinoid + AHA, etc.) — fast but imprecise, because a product categorised as "vitamin C" might contain a derivative that doesn't actually conflict. The second pass checks specific INCI names in each product's ingredient list (RETINOL, RETINAL, ASCORBIC ACID, GLYCOLIC ACID, BENZOYL PEROXIDE). This catches cases the subcategory pass misses and avoids false positives for products that fall into a broad category but don't contain the problematic ingredient. The deduplication step prevents the same product pair from appearing twice in the results when both passes flag it.
Barrier Stress Score Uses Position-Weighted Irritation
Ingredient irritation scores (0–5, from the INCI reference database) are weighted by ingredient position in the formula — ingredients listed earlier are present at higher concentrations. The weight decays linearly: 1 - (position - 1) × 0.05, floored at 0.1. This means a high-irritation ingredient at position 1 contributes full weight, while the same ingredient at position 15 contributes roughly half. Without position weighting, a product with salicylic acid as a preservative at position 20 would score the same as one with it as the active at position 3 — which misrepresents actual skin exposure.
GIN Trigram Index for Fuzzy Product Search
Product names in the skincare industry are notoriously inconsistent — "CeraVe Moisturising Cream", "Cerave moisturizing cream", "cerave-moisturising-cream" are all the same product. The Supabase schema uses PostgreSQL's pg_trgm extension with a GIN index on the normalized_name column (lowercased, hyphen-normalised). Queries use ilike with %pattern% matching against both the space-normalised and hyphen-normalised forms of the query. A relevance scoring function then re-ranks results in application code — exact matches score 1000, starts-with matches 500, word overlaps 50 per word — so the most relevant result surfaces first regardless of hyphenation or capitalisation.
Custom Products Without Database Registration
Users can add products that aren't in the database by entering a product name and a comma-separated ingredient list. The engine creates a createCustomProduct mock object that conforms to the full ProductWithIngredients interface, with ingredients parsed from INCI text and fragrance detection applied. This product flows through the same conflict, redundancy, and scoring logic as any database product. Custom entries use a custom-{stepOrder} ID prefix to ensure they never collide with database UUIDs. This matters because many niche, regional, or newly launched products won't be in OBF, and refusing to analyse them would exclude exactly the products users are most uncertain about.
Supabase RLS as the Auth Boundary
User routines are protected exclusively by Supabase Row Level Security policies — auth.uid() = user_id on all four operations. The application code never filters by user ID in queries; it relies on the database-layer enforcement. This eliminates a class of bugs where application-layer auth checks get bypassed by adding a new query path or forgetting to pass the user filter. The Supabase SSR client in the Next.js middleware propagates the session cookie so every server-side request uses the correct auth context without additional wiring.
A Working Ingredient Intelligence Tool
DaisyDerm runs end-to-end: users build a routine, receive conflict and redundancy analysis with cited severity levels, get a suggested application order, and see an overall score that accounts for their skin type. The OBF integration means the product database grows every time someone searches for a product that isn't already indexed. Custom product support means the tool is useful even when the database doesn't have coverage.
- Rule-based analysis engine with 9 conflict rules, 7 redundancy rules, and 4 missing-essential checks — all deterministic, auditable, and explainable
- Two-pass conflict detection (subcategory + INCI-level) with deduplication across passes prevents both false positives and duplicated warnings
- Barrier stress score (0–10) uses position-weighted irritation scoring — earlier ingredients carry higher weight, reflecting their higher concentration in the formula
- Skin-type-specific scoring penalties for oily (heavy occlusives), dry (stripping alcohols and SLS), sensitive (fragrance, menthol, drying alcohols), and combination skin
- Open Beauty Facts integration imports products and their full INCI ingredient lists on first search; rate-limited at 600ms between requests to stay within API limits
- GIN trigram index with application-layer relevance scoring surfaces the correct product regardless of hyphenation, capitalisation, or partial name entry
- Custom product support allows users to paste ingredient lists for unrecognised products — processed identically to database products through the full analysis pipeline
- Supabase RLS enforces user data isolation at the database layer; no application-code auth filtering required
What I Would Do Differently
The conflict rules are binary — a pair either conflicts or it doesn't. In practice, many ingredient interactions are concentration-dependent: a low-percentage AHA in a toner is very different from a 10% glycolic acid treatment. The INCI database already has irritation scores per ingredient; extending the conflict system to factor in ingredient position (as a proxy for concentration) would make the warnings more nuanced and reduce false positives for low-strength actives.
The OBF import categorisation uses keyword heuristics that fail on product names in languages other than English — a significant gap given that OBF has strong coverage of Korean, French, and Japanese products. A category classifier trained on product name + ingredient list pairs would be more robust than the current keyword-matching approach.